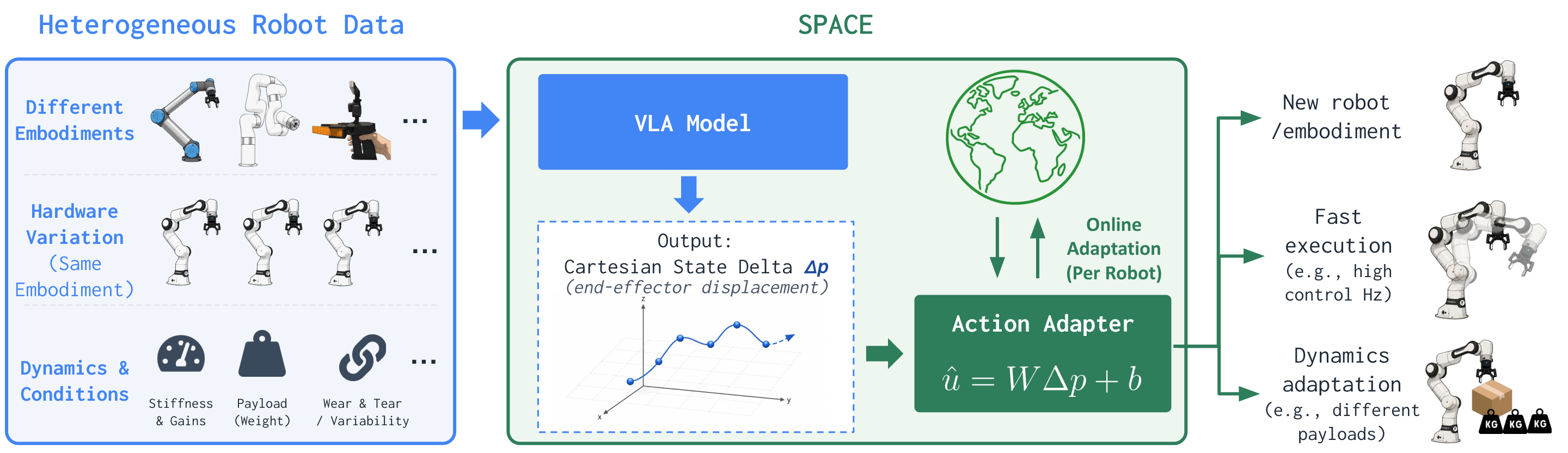
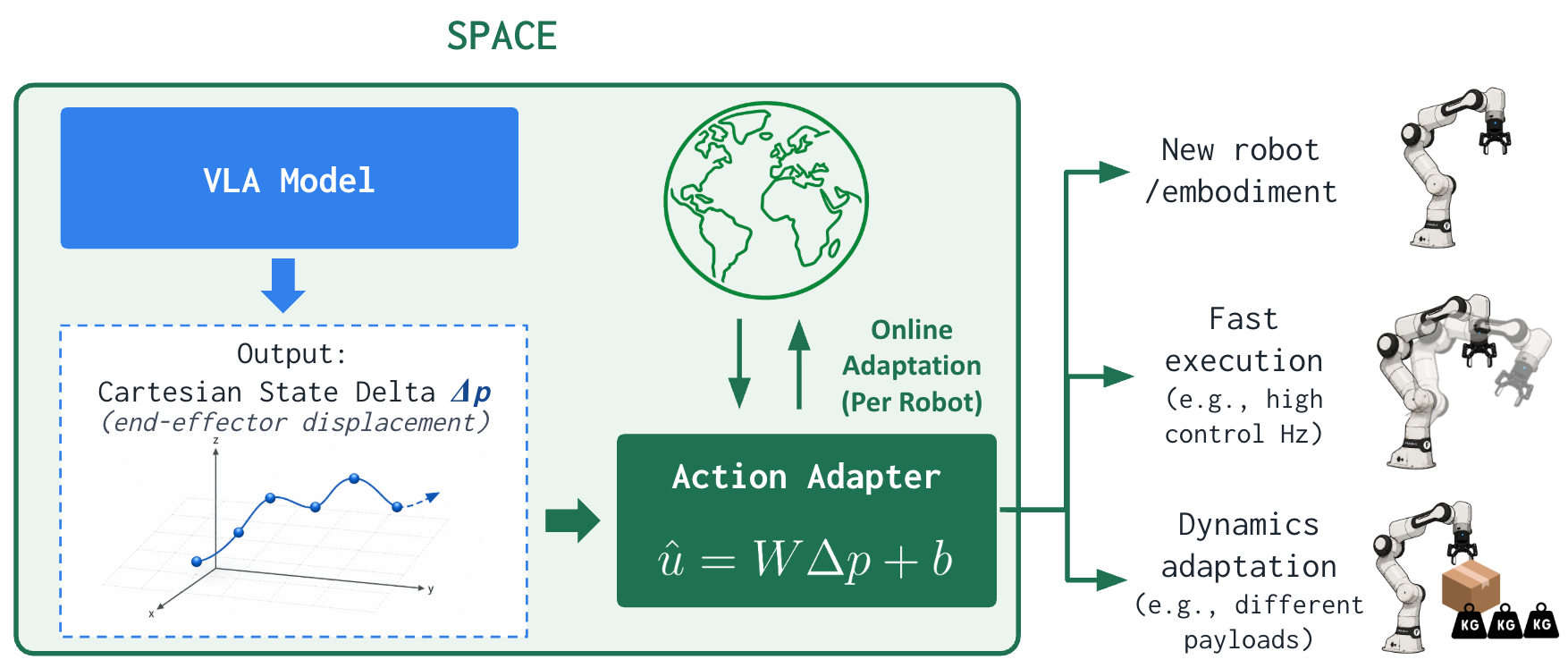
Experiments
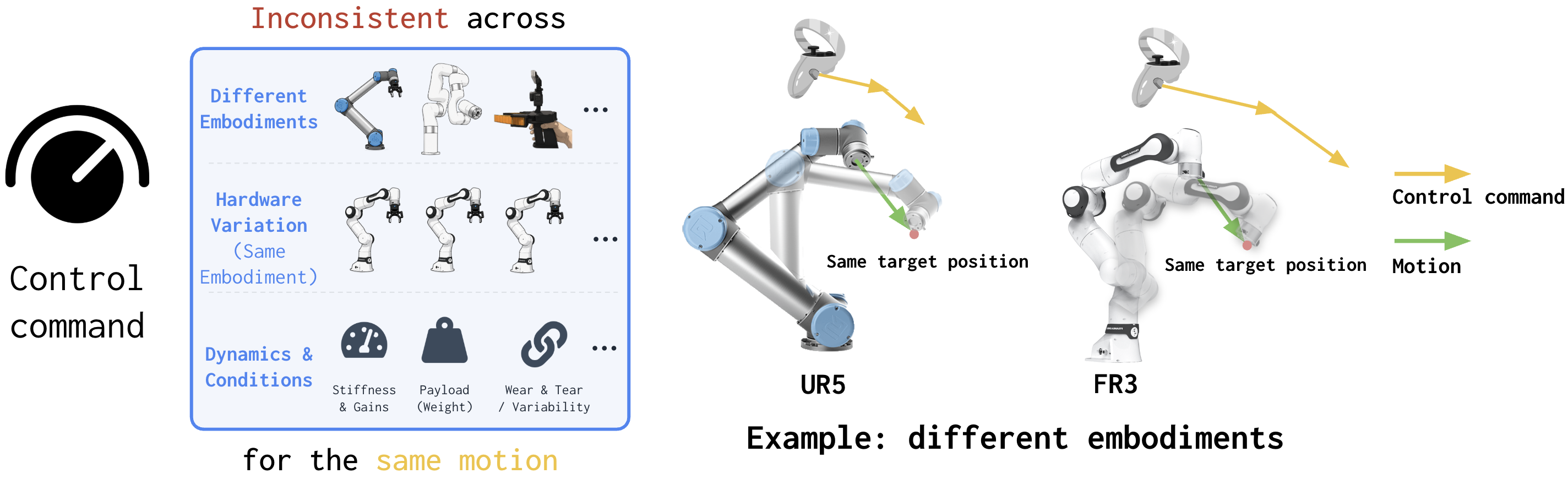
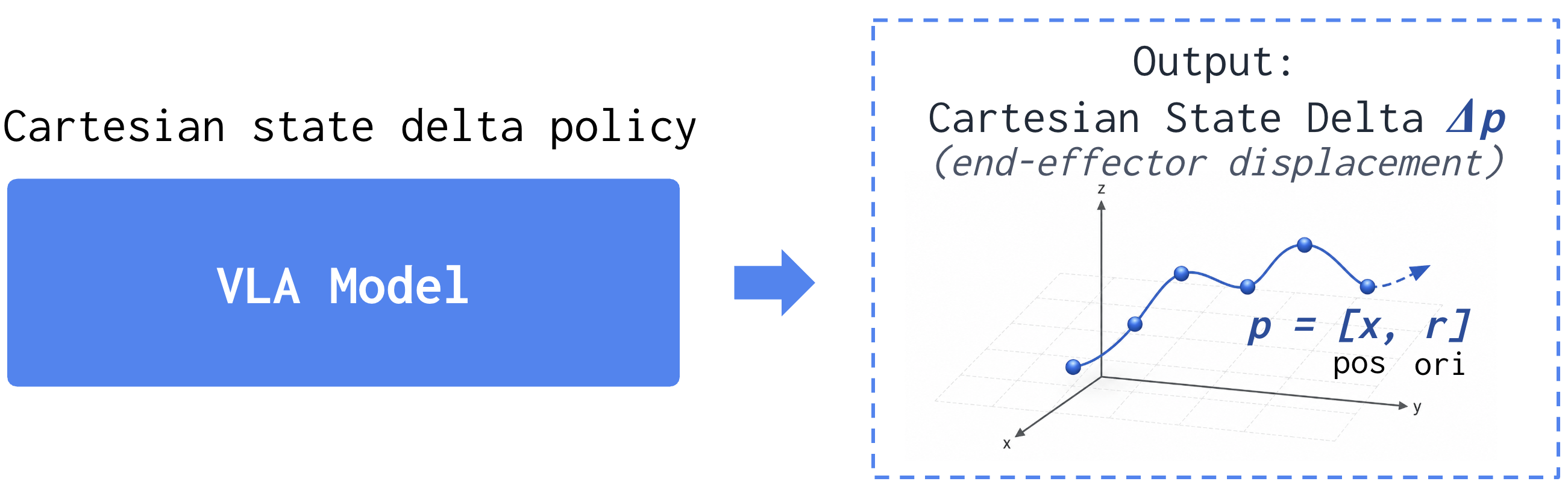
We compare SPACE against policy predicting control commands, referred to as Control command, which is common practice in policy learning. The \( \pi_{0.5} \) model is used.
Q1. Does SPACE improve cross-embodiment learning?
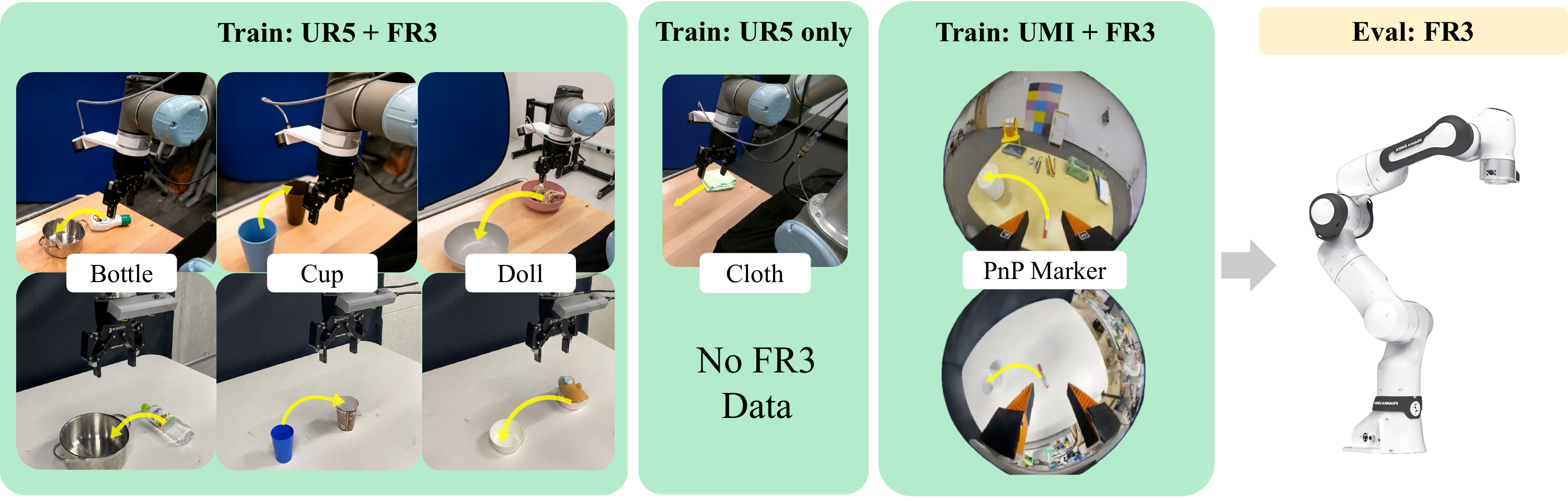
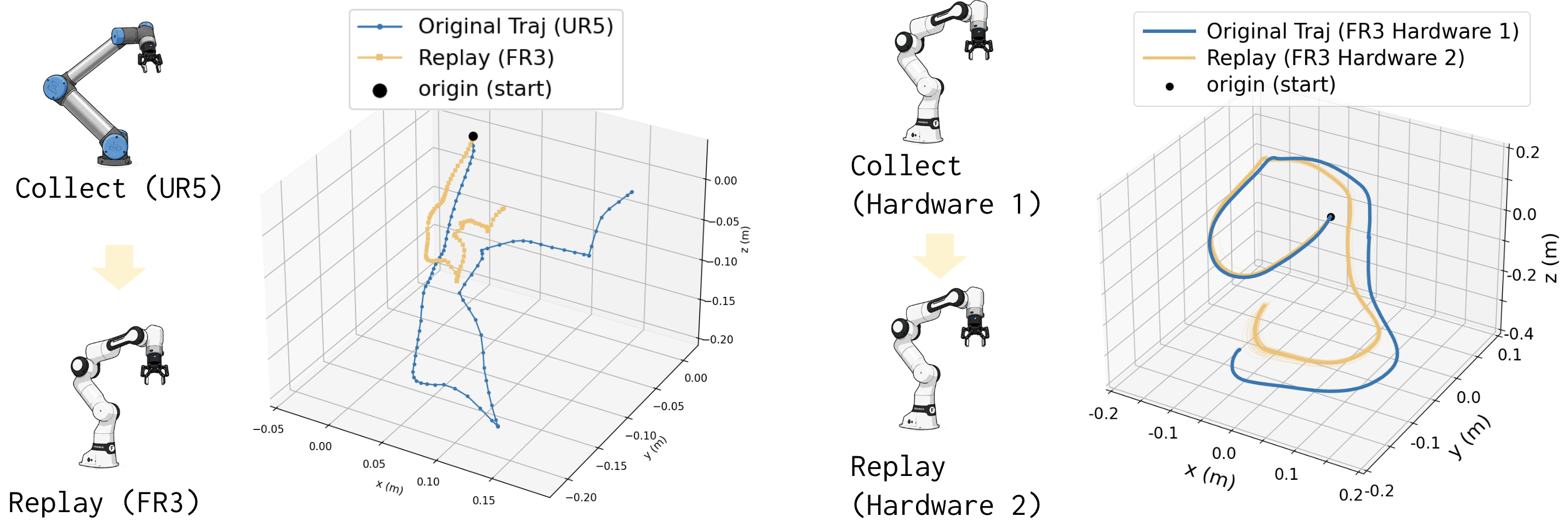
To test the effectiveness of SPACE, we experiment with co-training Franka Research 3 (FR3) data with UR5 data or UMI hand-held gripper data.
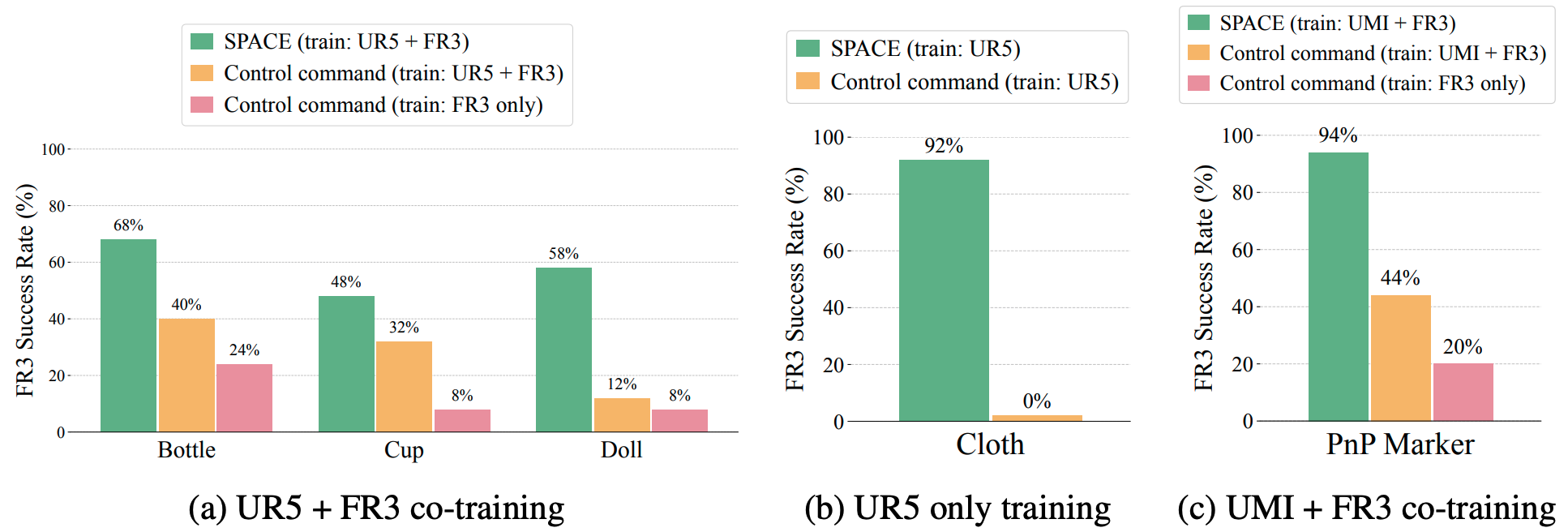
SPACE boosts co-training performance across UR5 and FR3 robots, and UMI human hand-held gripper and FR3 robot, while conventional policy of predicting control commands displays relatively low performances. This is because co-training using control command suffers from dynamics discrepancies between different embodiments. It even enables zero-shot execution of policy learned solely from UR5 data in FR3.
Q2. Does SPACE improve cross-hardware learning?
Even though the embodiment and controller implementation are the same, different hardware units exhibit discrepancies in dynamics due to wear and manufacturing variability.
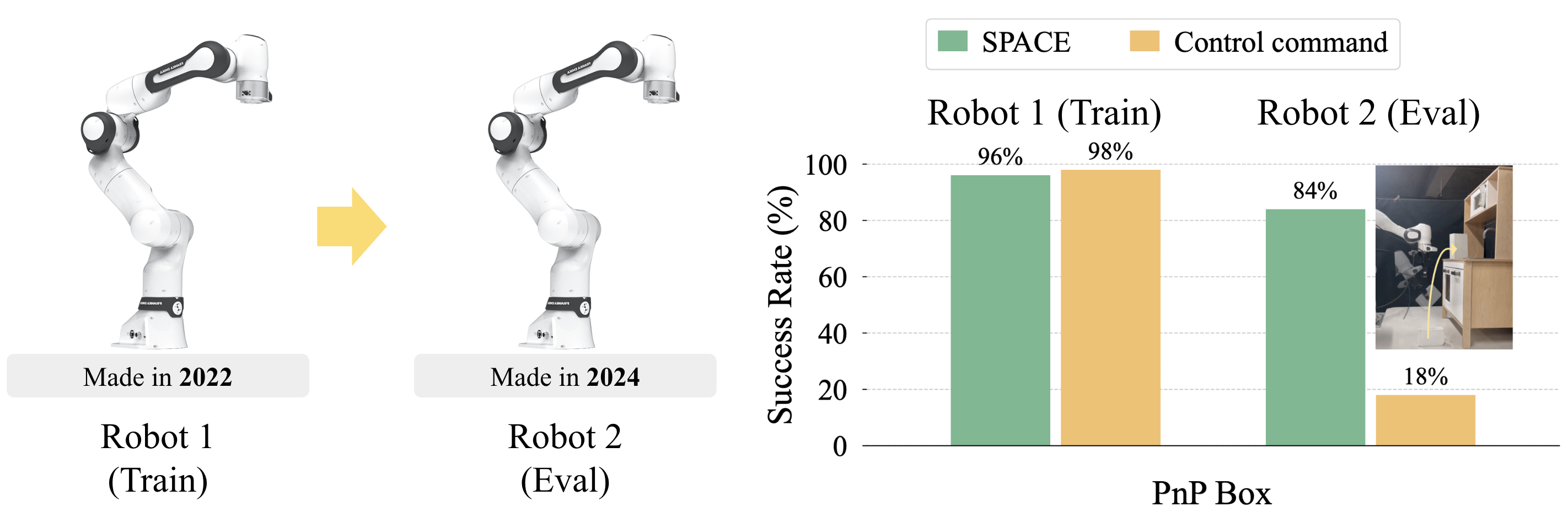
Execution in different hardware from training
For example, when deploying policy in robot not used during data collection, control command policy suffers from degradation due to subtle dynamics difference, while SPACE stays robust.
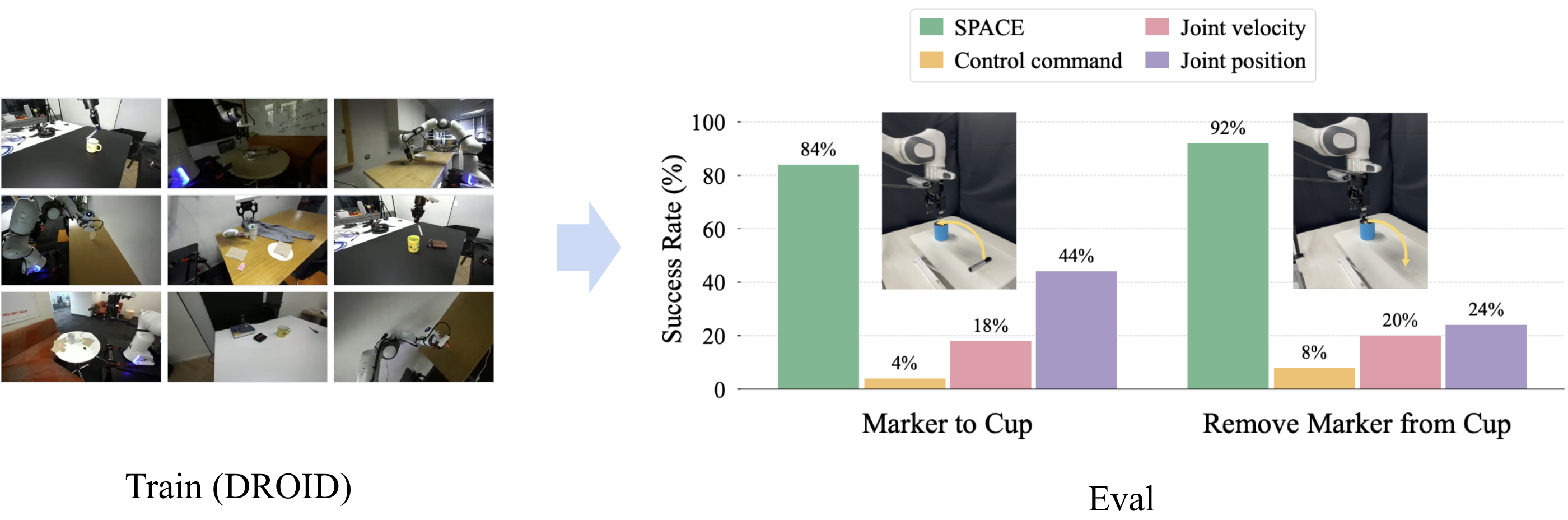
DROID success rate
SPACE achieves the best performance when learning from DROID data collected from multiple hardware units of the FR3 robot. This is because control commands are all specific to the data collection robot’s dynamics, which are inconsistent across different hardware units. We use the subset that involves an object "marker" to reduce the compute.
Q3. Does SPACE remain robust under a dynamics shift from training time?
SPACE can also adapt to the changes in environment dynamics from training. We collect training data using an empty box and put heavy metals during inference. In this setup, control command policy is unable to lift the heavy box and success rate drops to 0%. Meanwhile, SPACE adapts control command using Action Adapter to lift the heavy box and achieves 92% success rate.
Object weight change during deployment
SPACE can execute the policy under different control Hz. For example, we accelerate policy execution speed by increasing control hz to 30Hz, from 15Hz used during data collection. Meanwhile, policy predicting control commands degrades at 30 Hz due to discrepancy from training time.
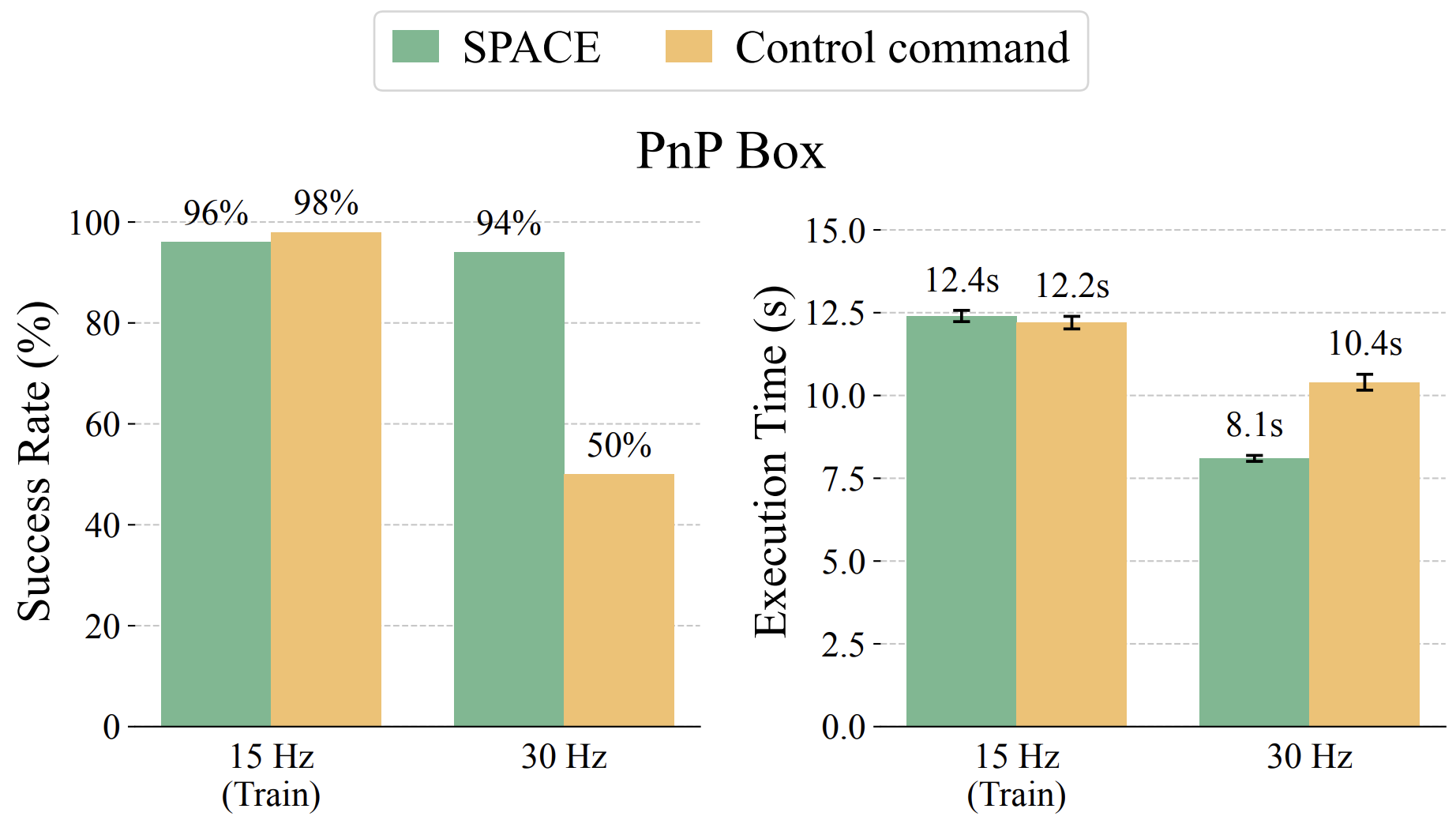
Control Hz change during deployment
(success rate & execution time)
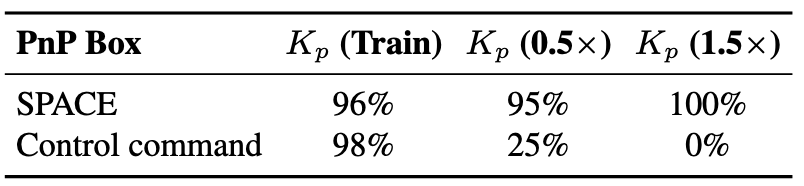
Gain change during deployment
(success rate)
SPACE can also execute under different controller gains from training time. Multiplying proportional gains (Kp) by 0.5x or 1.5x significantly drops success rates for control command policy while SPACE remains robust.
💡 Takeaway: By predicting dynamics-agnostic Cartesian state deltas for policy and adaptively converting them to robot-specific control commands, SPACE improves learning from different embodiments and hardware, and remains robust under varying dynamics at deployment.